Dataset Features

Distribution of devices

Distribution of dialects
3D-Speaker Datasets contains 10000+ speakers.
Device labels of all utterances are provided. Devices include phones, recording pens, PC laptops, microphone arrays, etc.
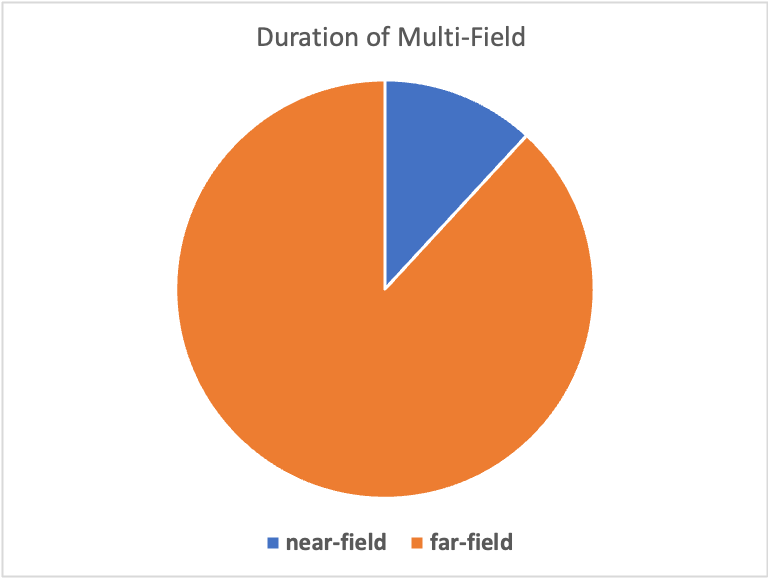
The distance from sound source to recording devices have been tracked and provided. Distances range from 0.1m to 4m, covering most common scenarios.
3D-Speaker-Datasets covers data of 14 different Mandarin dialects.
Please cite the following if you make use of the dataset.
@misc{zheng20233dspeaker,
title={3D-Speaker: A Large-Scale Multi-Device, Multi-Distance, and Multi-Dialect Corpus for Speech Representation Disentanglement},
author={Siqi Zheng and Luyao Cheng and Yafeng Chen and Hui Wang and Qian Chen},
year={2023},
eprint={2306.15354},
archivePrefix={arXiv},
primaryClass={cs.CL}
}The provided 3D-Speaker metadata is available to download under a Creative Commons Attribution-ShareAlike 4.0 International License(CC BY-SA 4.0).
Here is the train
dataset (~190G) of 3D-Speaker-Datasets.
md5: c2cea55fd22a2b867d295fb35a2d3340
Here is the test dataset (~1.1G) of 3D-Speaker-Datasets. md5: 45972606dd10d3f7c1c31f27acdfbed7
We also provide the transcription text for both train and test dataset.
Here are some text files: Cross-Device Trials, Cross-Distance Trials, Cross-Dialect Trials and Utterance informations.
You can also find more details and codes in our Github project.
The following table displays the state-of-the-art results on 3D-Speaker-Datasets.
If you would like your results to be listed on the leaderboard, please send the link of paper, EER and min-DCF(p_target=0.01, c_miss=1, c_fa=1), number of parameters, and code implementation(if available) to here.
| Model | Publications | # Params | Code and Materials | EER(%) | Min-DCF |
|---|---|---|---|---|---|
| ResNet34 + EDA + BDA-F | Huang et al. 24' | 8.25M | Supplementary Materials | 6.32 | 0.643 |
| ERes2Net-Large | Chen et al. 23' | 22.46M | Code Implementation | 6.43 | 0.611 |
| ERes2Net + EDA + BDA-F | Huang et al. 24' | 10.21M | Supplementary Materials | 6.93 | 0.672 |
| ERes2Net-Base | Chen et al. 23' | 6.61M | Code Implementation | 7.21 | 0.666 |
| CAM++ + EDA + BDA-C | Huang et al. 24' | 8.19M | Supplementary Materials | 7.61 | 0.734 |
| CAM++ | Wang et al. 23' | 7.2M | Code Implementation | 7.8 | 0.723 |
| ECAPA-TDNN | Desplanques et al. 20' | 20.8M | Code Implementation | 8.87 | 0.732 |
| Model | Publications | # Params | Code | EER(%) | Min-DCF |
|---|---|---|---|---|---|
| ResNet34 + EDA + BDA-F | Huang et al. 24' | 8.25M | Supplementary Materials | 8.27 | 0.730 |
| ERes2Net + EDA + BDA-F | Huang et al. 24' | 10.21M | Supplementary Materials | 9.22 | 0.750 |
| ERes2Net-Large | Chen et al. 23' | 22.46M | Code Implementation | 9.54 | 0.711 |
| CAM++ + EDA + BDA-C | Huang et al. 24' | 8.19M | Supplementary Materials | 9.66 | 0.757 |
| ERes2Net-Base | Chen et al. 23' | 6.61M | Code Implementation | 9.87 | 0.752 |
| CAM++ | Wang et al. 23' | 7.2M | Code Implementation | 11.3 | 0.783 |
| ECAPA-TDNN | Desplanques et al. 20' | 20.8M | Code Implementation | 12.26 | 0.805 |
| Model | Publications | # Params | Code | EER(%) | Min-DCF |
|---|---|---|---|---|---|
| ResNet34 + EDA + BDA-F | Huang et al. 24' | 8.25M | Supplementary Materials | 10.06 | 0.840 |
| CAM++ + EDA + BDA-C | Huang et al. 24' | 8.19M | Supplementary Materials | 10.60 | 0.844 |
| ERes2Net + EDA + BDA-F | Huang et al. 24' | 10.21M | Supplementary Materials | 11.28 | 0.861 |
| ERes2Net-Large | Chen et al. 23' | 22.46M | Code Implementation | 11.4 | 0.827 |
| ERes2Net-Base | Chen et al. 23' | 6.61M | Code Implementation | 12.3 | 0.870 |
| CAM++ | Wang et al. 23' | 7.2M | Code Implementation | 13.4 | 0.886 |
| ECAPA-TDNN | Desplanques et al. 20' | 20.8M | Code Implementation | 14.52 | 0.913 |
| Models | Publications | # Params | Code | trial cross device | trial cross distance | trial cross dialect | |||
|---|---|---|---|---|---|---|---|---|---|
| EER(%) | Min-DCF | EER(%) | Min-DCF | EER(%) | Min-DCF | ||||
| RDINO | Chen et al. 22' | 45.44M | Code Implementation | 20.4 | 0.972 | 21.9 | 0.966 | 25.5 | 0.999 |
| Model | Publications | # Params | Code | Accuracy(%) |
|---|---|---|---|---|
| CAM++ | Wang et al. 23' | 7.2M | Code Implementation | 29.36 |
We'll now clarify common questions about our dataset for you:
Question 1: The dataset is too large and we often experience interruptions during download. How can this be resolved?
Answer: We have split the data into several sub-files. You can download each sub-file separately and then merge them. Please verify the integrity of the files using the provided MD5 checksums. For specific filenames and download links, please refer to our code.
Question 2: It seems that some audio files in the dataset do not have transcripts provided?
Answer: Please note that each audio segments are recorded simultaneously by multiple devices, so the text annotations are identical across devices. For each utterance we provided text annotations on one of the devices. You can re-link text annotations to all audio segments using device ID and utterance ID. Please also note that text annotations are provided only on Mandarin Chinese utterances.